Лабораторне заняття 3. Робота з масивами та текстовими рядками
Мета роботи: освоїти роботу з масивами та текстовими рядками в мові С.
Теоретичні відомості
До складу кожного комп’ютера входить оперативна пам’ять (RAM), що зберігає дані для короткочасного використання. Навіть якщо дані зберігаються на жорсткому диску (або SSD) для довготривалого зберігання, коли в ці дані будуть вноситися зміни, вони будуть копіюватися в RAM. Не зважаючи на те, що обсяг RAM значно менший та вона є тимчасовою (поки не буде вимкнене живлення), вона значно швидша.
Можна розглядати пам’ять RAM, у вигляді сітки.
У мові програмування С, при створенні змінної типу char розміром в один байт, вона буде фізично збережена в одній з комірок сітки в RAM. Ціле число на чотири байти займе чотири таких комірки.
Масиви
В пам’яті можна зберігати змінні послідовно, одна за одною. І в мові програмування С список збережених змінних, які розташовуються в суміжних комірках пам'яті, називається масивом.
Розмірність масиву – це кількість індексів, необхідних для однозначної адресації елементів масиву. За кількістю використовуваних індексів масиви діляться на одновимірні, двовимірні, тривимірні і т.д. (рис. 3.1).
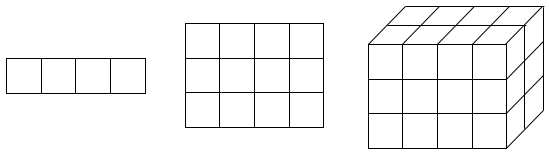
а) б) в)
Рисунок 3.1 – Розмірність масивів:
а) одновимірний; б) двовимірний; в) тривимірний
В найпростішому випадку масив має фіксовану довжину по всіх розмірностях і може зберігати дані тільки одного, заданого при описі, типу.
Нумерація елементів масиву в мові С завжди починається з нуля!
Розглянемо приклад програми Scores, реалізованої двома різними варіантами (рис. 3.2):
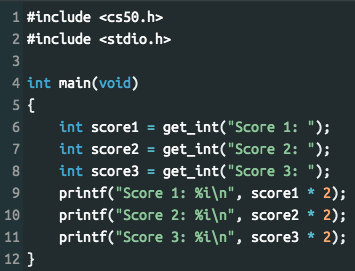

а) б)
Рисунок 3.2 – Програма Scores, реалізована
двома різними методами: а) без використання масивів; б) з використанням
масивів
Програма приймає значення трьох змінних від користувача, та виводить ці значення, збільшені в 2 рази. В даному випадку над змінними виконуються однакові дії, тому тут можна використати масив цілочисельних значень, кожна комірка якого буде виступати окремою змінною. Це дозволяє не лише зменшити об’єм коду програми (при збільшенні кількості змінних, в другому випадку об’єм коду не зміниться), але й спростити процес виконання над змінними різних операцій (можна задіяти цикли).
При використанні масиву в програмі, потрібно спочатку оголосити масив, вказавши його розмірність або заповнивши значеннями (рис. 3.2б, рядок 6), при чому розмір масиву, який вказується в квадратних дужках має бути визначений константою (в даному випадку – 3) чи змінною.
Звернення до певної комірки масиву відбувається за її індексом (рис. 3.2б, рядок 8), також вказаного в квадратних дужках. Не варто забувати, що нумерація комірок починається з нуля, тому індекс комірки завжди буде меншим за значення, що вказує на розмірність масиву.
Текстові рядки
Текстові рядки – це просто масиви символів. Це можна добре побачити в програмі Strings (рис. 3.3).

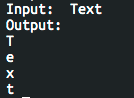
Рисунок 3.3 – Код програми Strings та результат її виконання
Програма приймає від користувача значення у вигляді текстового рядка та виводить на екран його посимвольно, працюючи як зі звичайним масивом.
Для початку, знадобиться ще одна нова бібліотека – string.h, яка містить функцію strlen(), що показує довжину текстового рядка.
На початку циклу ініціалізується дві змінні – i та n. Перша змінна використовується в якості лічильника, а в змінну n – буде записуватися довжина тексту (рис. 3.3, рядок 9). Це дозволить перевіряти умову, не вираховуючи довжину рядка кожного разу, а зробивши це лише один раз.
Коли текстовий рядок зберігається у пам’яті, кожен символ розміщується в одному байті в таблиці байтів. Наприклад, слово Zamyla збережено у 6 байтах. Але потрібен ще один байт, для позначення кінця рядка (рис. 3.4):
![]()
Рисунок 3.4 – Збереження тексту в пам’яті на прикладі слова Zamyla
Байт пам'яті, де збережено перший символ рядка (Z), позначено як s, оскільки змінна, в яку записується текст має саме таке ім’я. Далі, після останнього символу (a) розміщується один байт з усіма нулями для позначення кінця рядка. Байт з усіма нулями називається нульовим символом, який можна також позначати як \0.
Розглянемо приклад програми Upper, яка перетворює маленькі літери на великі (рис. 3.5):
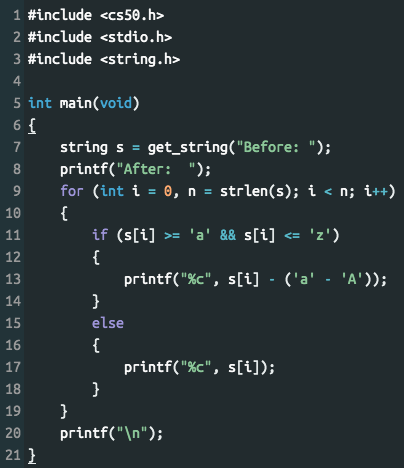
Рисунок 3.5 – Код програми Upper
Спочатку користувач вводить текстовий рядок s (рис. 3.5, рядок 7). Тоді, для кожного символу в рядку, якщо він в нижньому регістрі (його значення знаходиться між a та z – рис. 3.5, рядок 11), відбувається його конвертація на велику літеру (рис. 3.5, рядок 13). В іншому випадку він просто виводиться.
Перетворення малих літер у великі здійснюється шляхом віднімання різниці між малою (a) та великою (A) літерами (згідно таблиці ASCII).
Також можна використати готові функції з бібліотеки ctype.h, які можна використати для досягнення того ж ефекту (рис. 3.6):
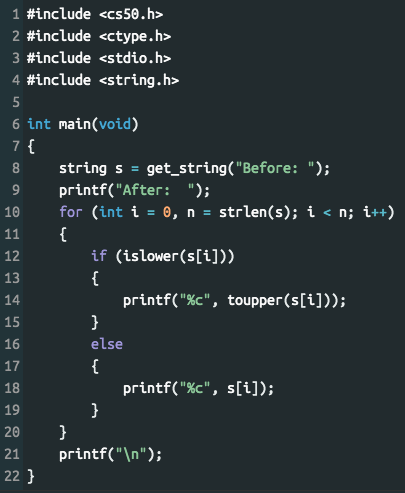
Рисунок 3.6 – Код програми Upper з використанням стандартних функцій
В даному випадку для перевірки належності символа до маленьких літер використовується функція islower() (рис. 3.6, рядок 12), а перетворення маленької літери на велику здійснюється за допомогою функції toupper() (рис. 3.6, рядок 14). Однак програму можна ще спростити, оскільки для використання функції toupper() ніякої перевірки islower() не потрібно, тому що вона перетворює лише маленькі літери, всі інші символи залишає без змін.