Лабораторна робота №12. Архітектурні розширення процесорів:
MMX, SSE і 3DNow!
Мета роботи: Вивчити призначення та функціональність архітектурних розширень процесорів: MMX, SSE і 3DNow!
1. Теоретичні відомості
Розширення MMX, введене Intel в останні моделі процесорів
Pentium, реалізувало принцип SIMD (одна інструкція на безліч операндів) для цілочисельної арифметики.
Пізніше фірма AMD розповсюдила цю ідею і на
деякі інструкції обчислень з плаваючою крапкою — це розширення 3DNow!, введене в процесори K-6 в 1998 році.
І, нарешті, в 1999 році з'явився процесор Pentium III з розширенням SSE. Всі ці
розширення розглядаються в даній лабораторній роботі.
1.1.
Розширення MMX
Прикладні програми все частіше використовують відтворення звуку і відео, високоточну тривимірну графіку і анімацію, багаті можливості мультимедіа. Зазвичай у таких програмах дані мають невелике число розрядів; однотипні операції виконуються над багатьма
даними; потік
команд рідко залежить від даних; потрібна висока продуктивність обчислень.
Процесори
сімейства x86 аж до п'ятого покоління працювали за традиційною схемою: по кожній
інструкції виконувалися дії над одним комплектом операндів. Операнди могли
знаходитися як в регістрах процесора, так і в пам'яті. Якщо в завданні було
необхідним виконання однотипних дій над безліччю операндів, то в програмний код
включався цикл для виконання інструкції стільки разів, скільки комплектів
операндів необхідно обробити. У додатках мультимедіа, 2D/3D-графіки,
комунікаційних і ряду інших сучасних завдань необхідність виконання однотипних
дій виникає достатньо часто і у великих об'ємах. Оптимізувати рішення цих
завдань була покликана технологія SIMD (Single Instruction — Multiple Data).
SISD (Single Instruction, Single Data):

SIMD (Single Instruction — Multiple Data):
Для її реалізації використовували регістри FPU (математичного співпроцесора чисел з плаваючою
крапкою), побудувавши на них обчислювальний блок MMX (MultiMedia eXtension). Традиційний FPU містить вісім
80-розрядних регістрів для зберігання і обробки чисел у форматі з плаваючою
крапкою. Ці регістри утворюють стік FPU і в
інструкціях адресуються через спеціальний покажчик стоку. Блок MMX фізично використовує по 64 молодших біта цих регістрів, причому ці
регістри адресуються прямо (MMX0...MMX7).
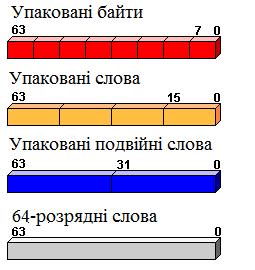
Команди технології MMX працюють із наступними
типами даних:
·
упаковані байти
(вісім байтів в одному 64-розрядному регістрі) - packed byte;
·
упаковані слова (чотири
16-розрядних слова в 64-розрядному регістрі) - packed word;
·
упаковані подвійні
слова (два 32-розрядних слова в 64-розрядному регістрі) - packed doubleword;
·
64-розрядні слова – quadword.
Технологія MMX повністю сумісна з попередніми процесорами архітектури
Intel. Всі програми, які створювалися раніше будуть працювати без змін і на процесорах з
технологією MMX.
У технології MMX використана модель обробки даних
SIMD (single instruction, multiple data, тобто одна команда - багато даних). Це підвищує продуктивність програм, оскільки одна
команда обробляє кілька елементів даних одночасно. MMX-команди забезпечують паралельну обробку
декількох байтів, слів або подвійних слів. Нижче можна побачити
приклад, що
моделює роботу двох графічних програм. Обидві програми виводять на екран одну і ту ж
послідовність кадрів. Перша програма написана без MMX-команд; вона
обробляє лише одну точку кольорового зображення (8 біт) за одну команду. У другій програмі застосована технологія MMX; її
команди здатні обробляти 8 точок (64 біт) одночасно!

Крім
того, логіка процесора поповнилася 57 новими інструкціями, розробленими
спеціально для більш ефективної роботи з відео, звуковими та графічними даними. (Всі нові інструкції мають коди в
заздалегідь зарезервуваному діапазоні,
тому перехід до нової технології не тягне за собою істотних витрат
на виробництво, і різкого збільшення
цін.) Для того щоб процесор зміг працювати з цими командами,
використовуючи розширення ММХ, розробники програмного забезпечення повинні
інтегрувати їх у програми. А для того, щоб
ММХ-додатки могли працювати на всіх комп'ютерах, вони повинні містити дві версії коду для процесорів - з MMX і без. Вісім 64-розрядних регістрів MMX фізично
використовують ті ж регістри, що й операції з
плаваючою крапкою._Подібне_рішення_забезпечує_повну_сумісність з_попередньою архітектурою_і,як_наслідок,повну_сумісність_із_широко поширеними_операційними системами та прикладним ПЗ. Однак
таке суміщення може знизити ефективність роботи в випадку
поперемінного використання звичайних обчислень з плаваючою точкою і роботи в режимі MMX
(на переключення з виконання MMX-інструкцій на операції з плаваючою крапкою
процесору вимагається 50
тактів). За твердженнями Intel, ці вдосконалення дають
10-20% збільшення швидкості для не-MMX додатків,
і більше 60% прискорення для MMX додатків. Найбільший ефект від використання ММХ-технології
може бути досягнутий в алгоритмах з наступними характеристиками:
- Малий розмір даних (Наприклад, 8-бітові
графічні піксели ,16-бітні звукові дані);
- Короткі, часто повторювані
цикли;
- Часті множення і накопичення;
Графіка
піксельних даних, як правило, представлена в 8-бітних числах,
або байтах. З технологією MMX, 8 з цих пікселів упаковані разом з
64-розрядними і перейшли
в регістр MMX, коли MMX інструкція виконується, вона приймає всі вісім
значень пікселів відразу з регістрів MMX, виконує арифметичні і логічні операції на
всіх 8 елементів паралельно, і записує результат в
регістр MMX.
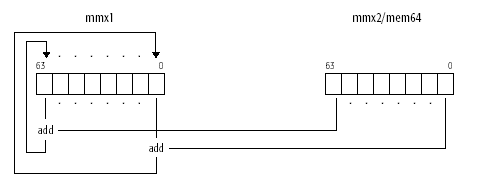
Кожна інструкція
MMX виконує дію відразу над всім комплектом операндів
(8, 4, 2 або 1), розміщених в регістрах, що адресуються. Ще одна особливість MMX — підтримка арифметики з насиченням (saturating arithmetic). Її відмінність від звичайної арифметики з циклічним переповнюванням
полягає в тому, що при виникненні перповнення в результаті фіксується максимальне
можливе значення для даного типу даних, а перенесення ігнорується. У разі
переповнення знизу, в результаті фіксується мінімальне можливе значення.
Граничні значення визначаються типом (знаковий або беззнаковий) і розрядністю
змінних. Такий режим обчислень зручний, наприклад, для визначення квітів. Нові
інструкції (всього їх 57) включають наступні групи:
·
арифметичні, серед яких складання і
віднімання в різних режимах, множення і комбінація множення і складання;
·
порівняння елементів даних на рівність або за величиною;
·
перетворення форматів;
·
логічні — І, І-НЕ, АБО і, що виключає АБО, виконувані
над 64-бітовими операндами;
·
зрушення — логічні і арифметичні;
·
пересилання даних між регістрами MMX і цілочисельними регістрами або пам'яттю;
·
очищення MMX — установка ознак порожніх регістрів в слові тегів.
Відмінність
в способі адресації регістрів, неспівпадання форматів даних MMX і FPU і деякі інші нюанси не
дозволяють чергувати інструкції FPU і MMX. Блок FPU/MMX може працювати або в одному, або в іншому режимі. Якщо,
наприклад, в ланцюжок інструкцій FPU потрібно
уклинити інструкції MMX, після чого
продовжити обчислення FPU, то перед
першою інструкцією MMX доводиться
зберігати контекст (стан регістрів) FPU в
пам'яті, а після цих інструкцій знову завантажувати контекст. На ці збереження
і завантаження витрачається процесорний час. В результаті виграш від ідеї SIMD можна повністю втратити. Збіг регістрів MMX і FPU виправдовують тим, що для
збереження контексту MMX при перемиканні
завдань не вимагалося доопрацювань в операційній системі — контекст MMX зберігається тим же способом, що і FPU, з яким уміли працювати відвіку. Таким чином, операційним системам було
все одно, який процесор встановлений — з MMX чи без. Але для того, щоб реалізувати переваги SIMD, додатки повинні “уміти” ними користуватися (і не програти на
перемиканнях).
![]()
1.2. Розширення 3DNow!
Підтримку цієї технології реалізували численні виробники апаратного та
програмного_забезпечення_(у_тому_числі_Microsoft). Підтримкою_3DNow! обзавелися
і відеокарти на чіпах провідних (nVidia, 3Dfx, S3, ATI) виробників. Весь цей час йшли розробки нового процесора AMD,
К7 (зараз Athlon). У ньому застосовується розширена технологія
3DNow!. Новий процесор був представлений в серпні 1999
року. AMD Athlon - процесор включає в себе певні удосконалення 3DNow! команд. Розширення
3DNow! Технологія реалізована в AMD Athlon приймає 3D мультимедійну продуктивність на новий рівень, і
спирається на 21 інструкцію AMD. Перший набір інструкцій x86 використовує суперскалярна
SIMD з плаваючою точкою. Розширена 3DNow! (Enhanced 3DNow!)
містить 24 інструкції: 19 мультимедійних інструкцій та 5 DSP (Digital
Signal Processor) інструкцій. Ці мультимедійні інструкції переносять поняття 3D
графіки на новий
рівень. 5 DSP інструкцій допомагають знизити утилізацію
(завантаження) процесора при використанні софт-модему, програвання МР3 файлів,
софт ADSL, Dolby Digital звуку. Технологія 3DNow! представляє собою новітнє
доповнення до архітектури x86-процесорів, спрямоване на значну інтенсифікацію
обчислень з плаваючою крапкою при обробці тривимірної (3D) графіки імультимедійних додатків. Переваги технології 3DNow! полягають в
видатної продуктивності при обробці_тривимірних_графічних_об'єктів,більше _реалістичному_і_життєвому_їхвідображенню. Крім_того,до_переваг_технології_3DNow! слід віднести_повноекранне
відео, звук і, звичайно, чудові можливості для роботи в Internet.
Крім прискорення 3D-ігор, 3DNow! технологія підвищує продуктивність
3D-розважального програмного забезпечення, програмне забезпечення
продуктивності бізнесу, CAD / CAE користувачів,
3D-звук, програмне забезпечення розпізнавання мовлення, обробки зображень 3D, MPEG2 відтворення відео і AC-3.
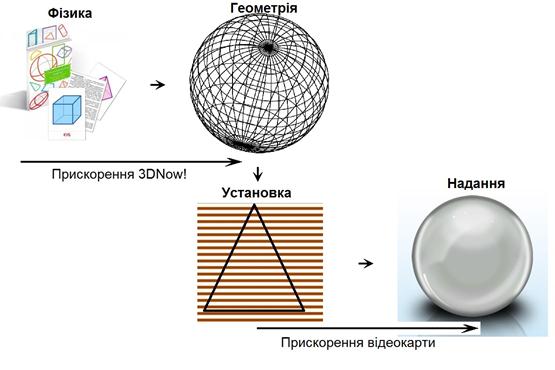
Обробка графічного конвеєра в 3DNow! може розглядатися в 4 етапи:
Фізика: центральний процесор виконує обчислення з плаваючою точкою інтенсивної фізики, створює імітацію реального світу і об'єкти в ньому.
Геометрія: Далі процесор перетворює математичні уявлення об'єктів в тривимірні зображення, використовуючи з плаваючою точкою інтенсивну 3D геометрію.
Установка: процесор починає процес
створення точки зору необхідності
для 3D-перегляду, а також графічний акселератор доповнює її.
Надання:
Нарешті, графічний прискорювач наносить реалістичні текстури
на комп'ютерні об'єкти, використовуючи в
розрахунках пікселі кольору,
тіні, і положення.
45 інструкцій, більше 20
мільйонів встановлених процесорів з технологією 3DNow!, підтримка величезного
числа виробників обладнання та програмного забезпечення.
1.3. Розширення XMM — SSE
Технологія була представлена в
процесорі Р3, на ядрі Катмай наприкінці 1999 року. Окрім нових мультимедійних інструкцій, в кожен Pentium III вбудований ідентифікаційний номер, який
дозволяє відстежити користувача. В одній з країн Європейського Співтовариства,
через це Рentium III
ввозити заборонили. SSE містить 71 інструкцію. Технологія не встигла отримати широкого поширення (чого
активно заважає наявність ідентифікаційного номера та виробничі проблеми
Intel). Підтримку SSE реалізовують виробники апаратного
та програмного забезпечення (також і Microsoft). До недавнього часу процесори Celeron не мали SSE,
але на початку 2000 року Intel випустила нові процесори Celeron з підтримкою
SSE (Coppermine128K). Технологія SSE дозволяла вирішити 2 основні проблеми MMX - при
використанні MMX неможливо було одночасно використовувати інструкції
співпроцесора, так як його регістри використовувалися для MMX і роботи з дійсними числами.
При виконанні нових інструкцій устаткування
традиційного FPU/MMX не використовується, що дозволяє ефективно використовувати
суміш інструкцій MMX з інструкціями над
операндами з плаваючою крапкою. Тут блоки процесора міняються ролями — регістри
традиційного співпроцесора використовуються для цілочисельних обчислень MMX, а обчислення з плаваючою крапкою (правда, тільки з одинарною точністю,
але для мультимедійних застосувань її вистачає) покладають на новий блок XMM.
У набір інструкцій цілочисельних MMX введені 12 нових операцій:
обчислення середнього, мінімуму, максимуму, сумарної різниці (сума модулів
різниці пар операндів), беззнакове множення і декілька інструкцій, пов'язаних з
перестановками елементів. Основне число нових інструкцій призначене для роботи
з блоком XMM. Арифметичні інструкції
включають складання, віднімання, множення, ділення, витягання квадратного
кореня, знаходження мінімуму і максимуму.
Нове
в SSE:
- Вісім 128-бітних регістрів XMM.
- 32-бітний MXCSR регістр прапорів.
- 128-бітний запакований одиничної точності із
плаваючою крапкою тип даних (тобто 4 числа з плаваючою крапкою).
- Інструкції над дійсними числами одинарної
точності, а також збільшено набір SIMD операції над цілими числами.
- Інструкції щоб зберігати і завантажувати стан
регістра MXCSR.
- Інструкції явною предвиборки даних, контролю кешування
даних і контролю порядку операцій збереження.
- Розширення інструкції CPUID. Використовується
для отримання інформації про процесор. З її допомогою програма може визначити тип
центрального процесора і його можливості (наприклад, які розширення підтримуються
процесором). У SSE додані вісім 128-бітних регістрів, які називаються XMM0 .. XMM7.
У SSE додані вісім 128-бітних
регістрів, які називаються XMM0 .. XMM7.
Кожен регістр може містити:
- Чотири 32-бітних значень з плаваючою точкою
одиничної точності;
- Два 64-бітних значення з плаваючою точкою
подвійної точності;
- Два 64-бітних цілих числа;
- Чотири 32-бітних цілих числа;
- Вісім 16-бітних цілих чисел;
- Шістнадцять 8-бітних цілих чисел або символів.
Є інструкції порівняння. Інструкції перетворення
зв'язують між собою цілочисельні формати (MMX і звичайні) і формати з плаваючою точкою XMM. Логічні інструкції включають операції І, АБО, І-НЕ і, що Виключає АБО над операндами в XMM.
Інструкції переміщення даних перерозподілу служать для
обміну даними між блоком XMM і
пам'яттю або цілочисельними регістрами процесора, а також для перестановок
елементів упакованих операндів.
Інструкції управління станом служать для збереження і
завантаження додаткового регістра стану XMM. Є також інструкції швидкого збереження/відновлення повного стану MMX/FPU
і XMM (блок пам'яті розміром 512 байт).
У SSE введені
нові інструкції управління кешуванням: з'явилися інструкції запису вмісту
регістрів MMX і XMM в пам'ять оминаючи кеш, що дозволяє уникати зайвого забруднення
кеш-пам'яті. З'явилася можливість “закачувати” необхідні дані в кеш до
інструкцій, що їх використовують.
Технології 3DNow! та SSE підтримують
4 операції за такт і можуть виконувати до 4 GFlops на частоті 1000МГц. Але інструкції 3DNow! простіше для виконання. SSE
включає в себе набагато більше інструкцій, оскільки архітектура Intel вимагає дублювання
керуючих функцій MMX, для чого необхідно виконувати дві інструкції, керуючі
операціями з плаваючою точкою - одну для SIMD-операцій та іншу для скалярних
операцій. Обидві технології мають інструкції для роботи з
кешем і потоковими даними. Найбільш вживаною і перспективної технологією на
поточний момент є 3DNow!.SSE на даний момент підтримує занадто мало додатків,
що пояснюється малою поширеністю процесорів, які підтримують цю технологію.
|
Виконавчі функції |
Enhanced 3DNow! |
SSE |
|
Виконання SIMD-обчислень з плаваючою точкою |
21 (Число інструкцій в
первинному варіанті технології 3DNow!) |
52 |
|
MMX (цілочисельні обчислення), додавання і переміщення
даних |
19 (Нові інструкції) |
19 |
|
DSP-розширення для комунікацій |
5 (Нові інструкції) |
0 |
|
Загальне число інструкцій |
45 |
71 |
71 інструкція, менше 5 мільйонів встановлених
процесорів з технологією SSE, обмежена підтримка виробників обладнання (NVidia не
зробила в GeForce апаратну
підтримку SSE) та програмного забезпечення.
2. Порядок виконання роботи
1.
Ознайомитися з теоретичними відомостями.
2.
Запустити програму та виконати дії з програмним
забезпеченням
3.
Закінчити роботу з програмою.
4.
Скласти звіт з власними висновками про проведену роботу.
Список рекомендованої літератури
1. Електронний дидактичний
комплекс. Нttp://elearning.lutsk.ua.
